The Transformer
The Transformer was presented in paper Attention Is All You Need, the interesting part of the proposed architecture lie in the used attention mechanism that I try to explain in the following post.
You can find an implementation of the Transformer here.
Scaled Dot-Product Attention
The attention mechanism used is depicted by the following equation:
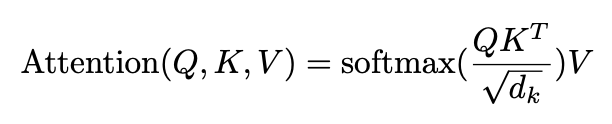
where Q, K, V and dk are respectively the queries, the keys, the values and the keys dimension.
We can describe what Q, K, V are like:
- Q - query : Input token we currently looking at (a vector)
- K - keys : The tokens we compares to the query (a sequence of vectors)
- V - values : A sequence of vectors used to store the final embedding representation of tokens
The purpose of this attention mechanism is to create, for each token in a sequence, a new contextual representation that enrich token embedding with information of the other tokens in the sequence. (it's completely performed in the Transformer architecture by the use of multiple heads and the Feed-Forward network that create our final embedding)
This attention is composed of 3 important steps, let's see them through an example.
We have the following sentence : my random sentence
We embeds it into a sequence of vectors : S = [emy, erandom, esentence]
We creates Q, K, V matrices by linearly project each word embedding into embedding of dimension dk for the queries and keys, and dimension dv for the values (for simplicity, we use dk=dv=2).
So we have 3 matrices for queries, keys and values projections : WQ, WK, WV
- SWQ = Q
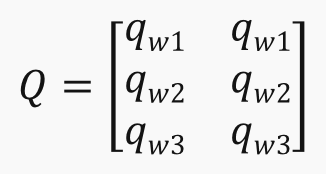
- SWK = K
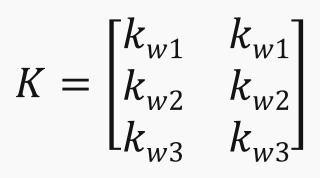
- SWV = V
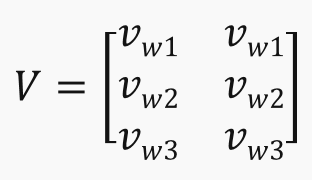
- First step - Compares each query to each key
- Second step - Computes a Score matrix by dividing the matrice obtain at step 1 by sqrt(dk) then normalize it using the softmax function
- Last step - Computes our final matrice as the weighted sum of word representation with their attention scores
Multi-Head Attention
In previous section we depicted the mechanism of one attention head so the multi-head attention is realized by using as many heads as you want then you just have to concatenate the results of each head to finally perform a final projection to obtains the output matrice.
Site Map:
- Home Page -> Home Page
- Transformer -> Transformer
- Neural Plasticity -> Neural Plasticity
- Automatic Speech Recognition -> ASR
- Spiking Neural Network -> SNN
- Curriculum Vitae -> CV
- Contact page -> Contact