Speech To Text
Links that I found usefull when working on STT.
Datasets
- Blog of a list of Voice Datasets -> 9 voice datasets
- openSLR dataset -> LibriSpeech ASR corpus
- VoxForge Dataset
- TensorFlow Speech Recognition Challenge
- Common Voice corpus
- VoxCeleb
Preprocessing Data
- Great blog about audio signal preprocessing -> Speech Processing
- Python Library -> pyfilterbank, Librosa, SoundFile
- Kaggle example -> Speech Recognition Challenge
Papers
- Towards End-to-End Speech Recognition with Reccurent Neural Networks
- Deep Speech
- Deep Speech 2
- Listen, Attend and Spell (LAS)
- LAS 2
- CTC
- Syllable-based Seq2Seq Speech Recognition with Transformers
- Multilingual End-to-End Speech Recognition with A Single Transformer on Low-Resource Languages
My github repository with some ASR experiments -> ASR
Usual approaches for Automatic Speech Recognition (ASR) use different modules (Acoustic Modeling, Pronunciation Modeling, Language Modeling) trained separately and often hand-designed.
Seeing deep learning improvement (optimization, data usage) over past years, it is possible to consider and design an End-to-End algorithm to perform ASR.
Multiple architectures were proposed using Recurrent Neural Network (RNN). Two main way appear, one using Connectionist Temporal Classification (CTC) based models and the other using Sequence-to-Sequence framework with Attention.
All those approaches use Spectrograms as input features and produce character level outputs. They use Beam search and potential Language Model (LM) to improve scores.
One major problem for ASR with labeled data is the alignment between the audio sources and the transcripts which is partially handle by CTC based models or by the attention mechanism in Seq-to-Seq framework.
HMM and CTC models made a strong assumption about frame-independence, Seq2Seq models remove this assumption allowing them to learn an implicit LM and optimize WER more directly. (WER - Word Error Rate is the usual metric used to measure ASR models performance)
All those approaches are computationally heavy, and the recurrence used made parallelization impracticable.
- Input representation
In the litterature, we usually found the use of Filter Banks or Mel-Frequency Cepstral Coefficients (MFCCs) as input features. They comes from extensive human engineering that aim to simulate how the human ear works.
For my Speech-to-Text(STT) project, I've decided to go on an End-to-End design, even for the input. Learning to perform STT task directly from raw signal is really hard and in the current state of our knowledge on artificial neural network(ANN), it requires too much labeled data. When you think about ourself, even with our advance big neural network designed through evolution, we are exposed to a lot of sound signal and it takes us almost a year to show sign that we understand some simple interaction and 3 years and more to be able to use words. We have leverage some labeled data when our parents repeat the same sound when pointing to a single object but most of our learning seems to be self-supervised. There is a lot of unlabelled sound data in the web, so maybe we can leverage it to allow our ANN to perform well at the task.
The first technic that came to my mind is Predictive Coding(PC) where the theory is that the brain creates and maintains a model of the environment by predicting the futur and compare its prediction to the reality. So, to creates our features representation in a self-supervised way, we can design an ANN that will first downsample the signal, using a convolutional network for example, to obtain a more compact representation (we can add a sparsity constraint on this representation), then we use another neural network, which can also be a convolutional network (using transposed convolution), to recreates the signal and the loss could be a simple Mean Squared Error(MSE). (One work that I found particularly interesting in this field is SDPC) The problem is that it will be computationally intensive and you will certainly struggle to fit, in your GPU, a big enough architecture that will have a good performance.
Indeed, the usual sample rate of an audio signal is 44.1Khz. It means that you have 44,100 numerical values to describe each second of your record so even with a 2s audio record you will have an array of shape (88200,). In the case of openSLR dataset, the sample rate choosed is way lower, 16Khz, but it still give you big arrays for even small records.
Another option could be a technic called Contrastive Learning (or Contrastive Predictive Coding).
- Architecture review
Browsing the literature on Speech-to-Text task, we found various kind of architecture. Let's see some and their pytorch implementation.
The most famous one for the moment in NLP field, the Transformer.
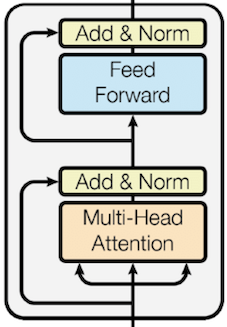
Even if there is now an official implementation in pytorch, I've made at the time my own and I've add option to use the version propose in the paper Stabilizing Transformers For Reinforcement Learning. You can find it here.
Taking ideas from papers han2019, wu2019pay, kriman2020quartznet and hannun2019sequence we can creates 4 differents convolution architecture:
-
Separable Convolution:
-
Basic convolutional block:
-
Convolution attention from Lightconv:
-
Combination of a ConvBlock and an AttentionConvBlock:
We can also add a simple feed-forward network:
Now with these building blocks, we can create our network:
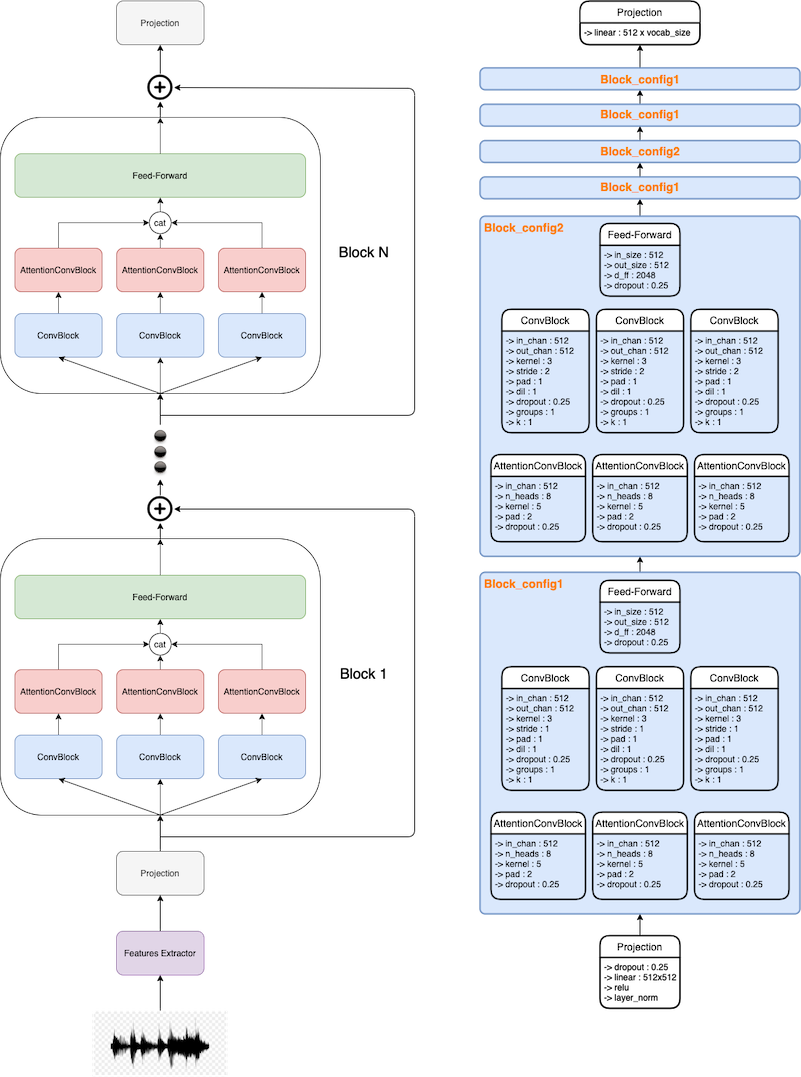
where the features extractor is wav2vec, the input projection and final projection are simple linears.
The model is made of multiple layers with multiple blocks, to allow multiple configurations using the same class model, we can design our class to be block/layer agnostic.
- Possible losses
- ASG & CTC -> ASG-CTC, CTC, CTC paper
- Cross-Entropy in the case where alignment is handle by using attention mechanism
- Experiments
You can find the code of an experiment that use the previous described architecture with CTC-loss and obtain a WER of 0.057 in my repository: ctc_experiments.py
Site Map:
- Home Page -> Home Page
- Transformer -> Transformer
- Neural Plasticity -> Neural Plasticity
- Automatic Speech Recognition -> ASR
- Spiking Neural Network -> SNN
- Curriculum Vitae -> CV
- Contact page -> Contact